Druid 성능 평가¶
Druid는 〈실시간〉 탐색이 가능한 데이터 스토어를 지향하는 만큼 수치화된 성능을 평가함에 있어서는 다음의 두 가지 측면에 초점이 맞춰집니다.
Query latency
Ingestion latency
쿼리 처리와 ingestion에서 소요되는 시간을 최소화하는 것이 〈실시간’을 이루는 핵심이 되기 때문입니다. 지금까지 Druid 개발진을 비롯한 여러 기관 및 개인이 이러한 기준으로 Druid 성능을 평가한 benchmark들을 산출하고 그 밖의 지표를 통해 Druid를 다른 데이터베이스 관리 시스템들과 비교한 결과를 공개하였습니다.
Druid 개발진의 자체 평가¶
Druid 개발진이 2014년 발표한 백서 〈Druid: A Real-time Analytical Data Store〉1의 Chapter 6 Performance에서는 Druid의 query 및 ingestion latency를 다방면에서 평가한 결과를 상세하게 설명하고 있습니다. 본 절에서는 이 중에서 Druid의 성능을 직관적으로 살펴볼 수 있는 지표 위주로 간단히 소개합니다.
Query latency 성능¶
Druid의 query latency 성능에 대해 백서에서는 현장에서 실제 사용되는 데이터셋 8종과 TPC-H 데이터셋에 대한 쿼리 결과를 기준으로 평가하였는데, 여기서는 TPC-H 데이터셋에 대한 쿼리 결과를 소개합니다. TPC-H 데이터셋에 대한 query latency는 MySQL과의 비교 평가 방식으로 진행하였고, 이때 사용한 클러스터 사양은 다음과 같았습니다.
Druid historical 노드: Amazon EC2 m3.2xlarge instance types (Intel® Xeon® E5-2680 v2 @ 2.80GHz)
Druid broker 노드: c3.2xlarge instances (Intel® Xeon® E5-2670 v2 @ 2.50GHz)
MySQL Amazon RDS instance (Druid와 동일한 m3.2xlarge instance type)
아래는 단일 노드에서의 1GB 및 100GB TPC-H 데이터셋에 대한 Druid와 MySQL의 query latency를 비교한 결과를 정리한 그래프입니다.
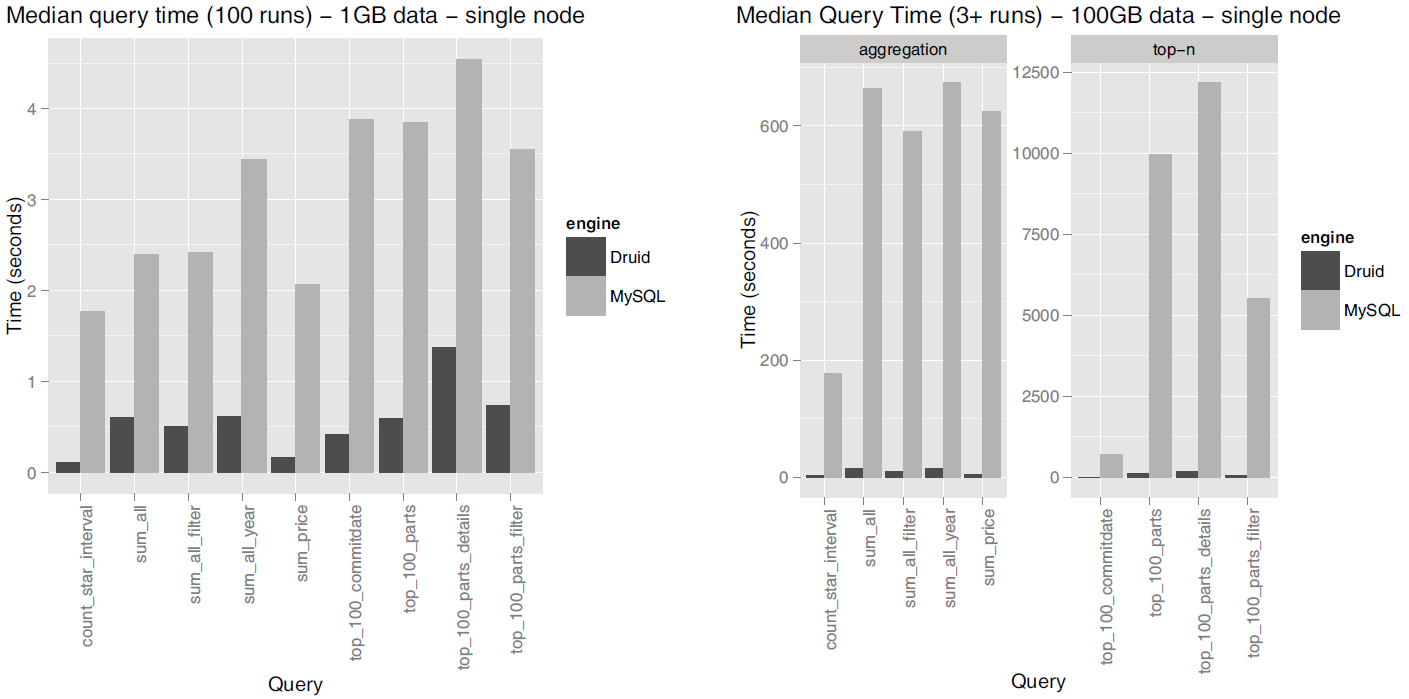
Source: Druid: A Real-time Analytical Data Store¶
이러한 결과는 Druid의 도입으로 기존 관계형 데이터베이스 시스템에 비해 획기적으로 빠른 쿼리 속도를 낼 수 있음을 시사합니다.
또한 여러 노드를 엮어서 클러스터를 구성할 경우 쿼리 처리 속도가 어느 정도 향상되는지도 측정하였습니다. 쿼리 대상 데이터셋으로서 100GB TPC-H를 사용하였으며 단일 노드(8개 코어)와 6개 노드 클러스터(48개 코어) 간의 성능 차이는 다음과 같았습니다.
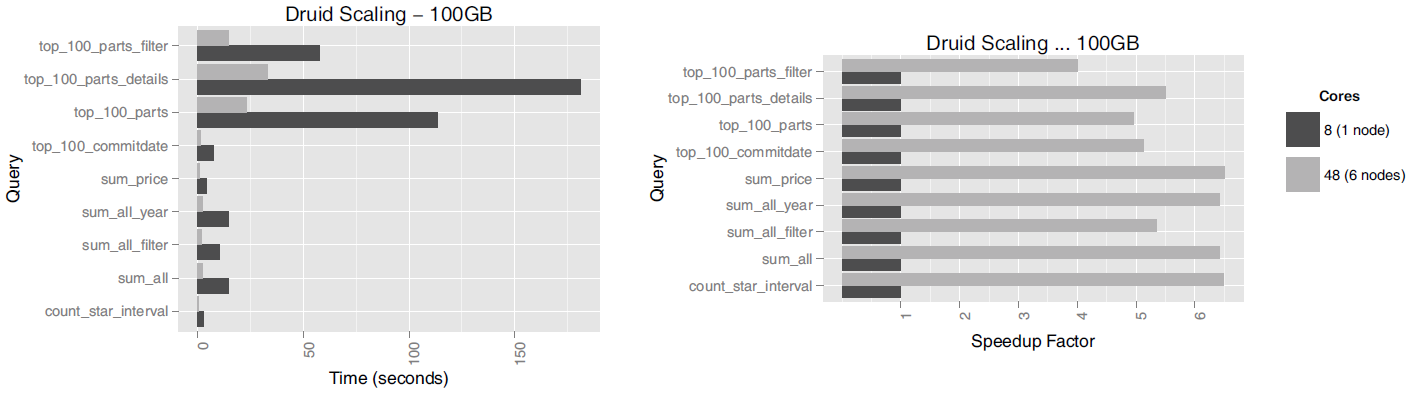
Source: Druid: A Real-time Analytical Data Store¶
모든 쿼리가 linear scalability를 달성하지는 않았으나 상대적으로 단순한 쿼리들의 경우에는 거의 코어 수에 정비례하는 처리 속도 증대를 보여주었습니다(SK텔레콤 Metatron에서는 더욱 뚜렷한 linear scalability를 달성할 수 있도록 기능을 보강하였습니다).
Ingestion latency 성능¶
Druid의 ingestion 성능에 대해서도 평가하였는데, 이때 사용된 클러스터 환경은 다음과 같았습니다.
6개 노드, 총 메모리 360GB 및 96개 코어(12 x Intel® Xeon® E5-2670)
ingestion 대상으로는 현장에서 실제 사용되는 데이터 소스 8종이었으며 데이터 소스 각각의 특징과 ingestion 결과는 아래와 같았습니다. 참고로 ingestion 측정을 하는 기간 동안 해당 클러스터에서는 그 외 다른 데이터 소스에 대한 ingestion 동작도 병행해서 실시하였습니다.
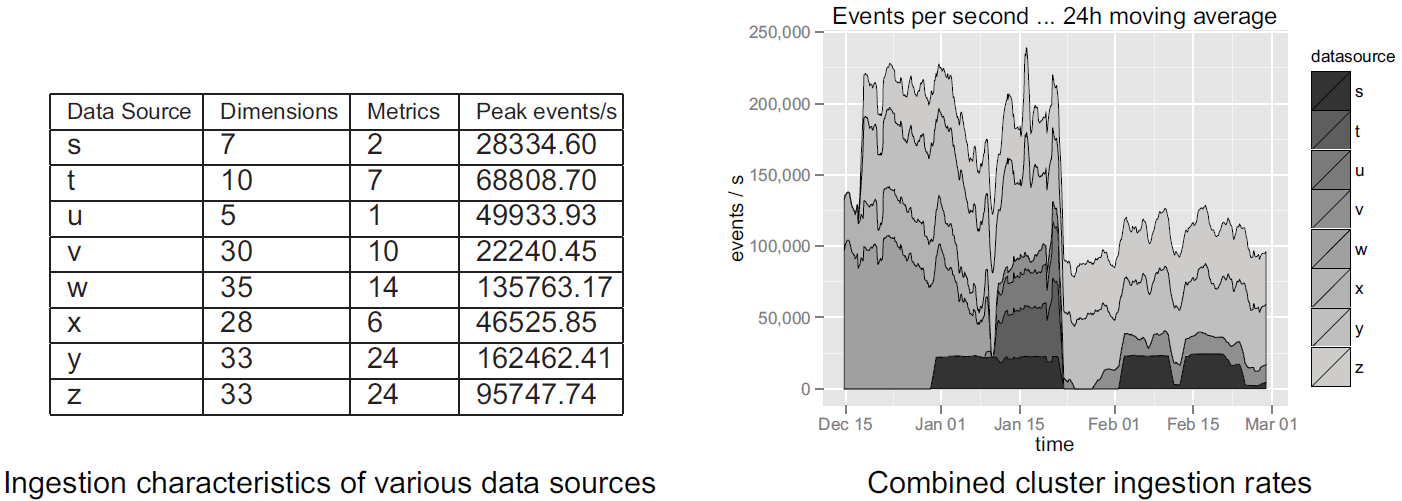
Source: Druid: A Real-time Analytical Data Store¶
데이터 ingestion 속도는 데이터의 복잡성 등 여러 가지 변수의 영향을 받지만, 측정 결과를 놓고 볼 때 대체로 〈interactivity’라는 Druid의 개발 목표에 부합한다고 할 수 있습니다.
SK텔레콤의 Druid 성능 평가¶
SK텔레콤에서는 다음과 같이 Druid의 query latency와 ingestion latency를 측정하였습니다.
Query latency 테스트¶
Query latency를 측정하는 조건은 다음과 같았습니다.
데이터: TPC-H 100G dataset (9억 rows)
Pre-aggregation 기준: day
서버: r3.4xlarge nodes, (2.5GHz * 16, 122G, 320G SSD) * 6
Historical 노드 개수: 6개
Broker 노드 개수: 1개
그 결과 TPC-H 100G dataset의 5개 쿼리의 반환 속도는 다음과 같았습니다(Hive의 쿼리 처리 속도도 참조용으로 함께 측정하였습니다).
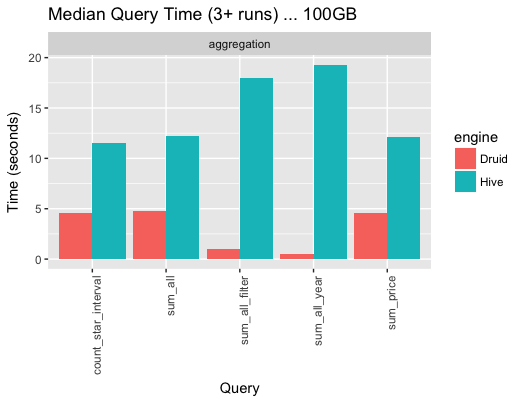
Source: SK Telecom T-DE WIKI Metatron Project¶
참고
Hive의 benchmark가 현저하게 떨어지는 원인 중 일부는 Thrift로 측정한 것과 partition없이 test set이 구성되어 있기 때문입니다.
Ingestion latency 테스트¶
Ingestion latency를 측정하는 조건은 다음과 같았습니다.
Ingestion data size: 1일 30억 rows, 10 columns
메모리: 512 GB
CPU: Intel (R) Xeon (R) Gold 5120 CPU @ 2.20 GHz (core 56개)
Historical 노드 개수: 100개
Broker 노드 개수: 2개
총 10개의 middle manager 노드 중 3개에서 job 수행
Ingestion 도구: Apache Kafka
이와 같은 조건으로 data ingestion을 100회 수행하였고 평균 ingestion latency는 1.623439초였습니다. 여기서 ingestion latency는 아래 도식화한 것과 같이 Kaka ingestion, Druid ingestion, Druid query 처리에 소요되는 시간을 모두 합산한 것입니다.
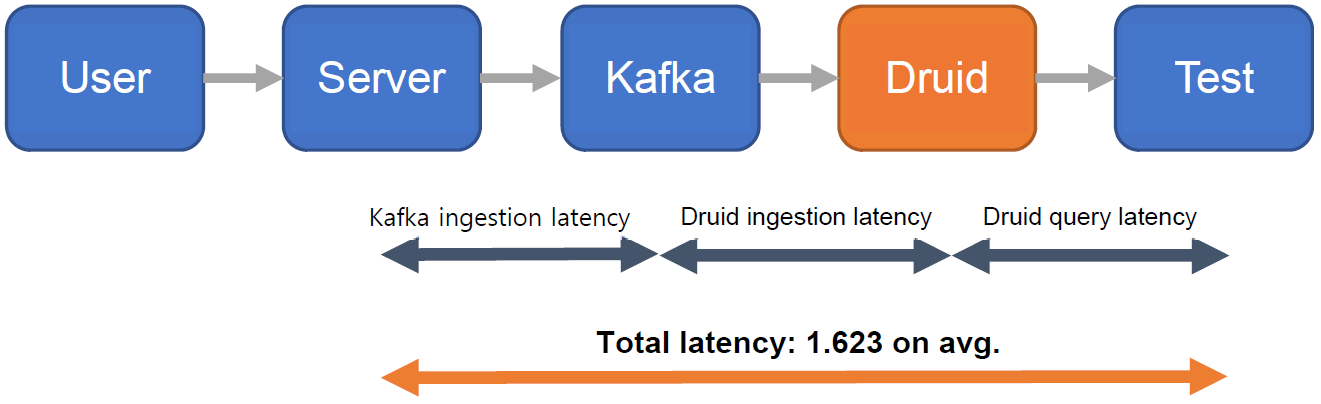
Source: SK Telecom T-DE WIKI Metatron Project¶
Druid에 대한 제3자의 평가¶
Outlier의 Druid 평가¶
다음은 Outlier 블로그에 2016년 8월 26일에 게재된 Top 10 Time Series Databases라는 포스트2에서는 20개의 주요 오픈소스 시계열 데이터베이스 시스템을 평가하였습니다. 기고자인 Steven Acreman이 개인적으로 매긴 성능 랭킹에서 Druid는 20개 중 9위를 차지하였는데, 여기서 밝힌 Druid의 주요 성능은 다음과 같습니다.
Outlier의 주요 Druid 평가 내용¶ 평가 기준
Druid의 성능
쓰기 성능 - 단일 노드
25k metrics/sec
출처: https://groups.google.com/forum/#!searchin/druid-user/benchmark%7Csort:relevance/druid-user/90BMCxz22Ko/73D8HidLCgAJ쓰기 성능 - 5개 노드 클러스터
100k metrics/sec (추산 결과)
쿼리 성능
양호
개발 수준
안정적인 제품을 제공하는 단계에 이름
장점
괜찮은 데이터 모델이면서 좋은 분석 도구 기능들을 갖추고 있음. 주로 batch 로드된 대량 데이터셋에 대해 신속하게 쿼리하는 데 사용되도록 설계되었으며, 이 점에서 탁월한 성능을 보임.
단점
시스템 운용이 힘듦. 쓰기 처리 속도가 아주 빠르지는 않음. 실시간 ingestion 셋업이 까다로움
DB-Engines의 Druid 평가¶
온라인 웹사이트 DB Engines3에서는 다양한 데이터베이스 관리 시스템(DBMS)의 시장 인기도를 매달 평가하며, 이때 다음과 같은 지표를 사용합니다.
인터넷에서 언급되는 횟수: Google, Bing, Yandex에서의 검색 결과로 측정
일반적인 관심: Google Trends에서의 검색 빈도를 기준으로 측정
기술 토론 빈도: 유명 IT 관련 Q&A 사이트인 Stack Overflow 및 DBA Stack Exchange 포스팅 현황을 기준으로 측정
구인 게시글 수: Indeed 및 Simply Hired의 게시글을 기준으로 측정
해당 커리어를 지닌 인재의 수: LinkedIn 및 Upwork에 게시된 프로필을 기준으로 측정
SNS에서의 언급 수: Twitter의 트윗수를 기준으로 측정
그 결과 Druid는 2018년 7월 기준으로 총 343개 시스템 중에서 118위를 차지하였고, 그 중 시계열 데이터베이스 시스템만을 두고 집계했을 때 총 25개 시스템 중 7위를 차지하였습니다.
Apache Spark와의 비교¶
Druid를 Apache Spark와 비교하는 것은 상당히 의미 있는 작업입니다. 둘 다 차세대 대용량 데이터 분석 솔루션으로 각광 받고 있으며, 서로 다른 장점을 가지고 있어 매우 상호보완적으로 조합이 가능하기 때문입니다. Metatron에서도 Druid를 데이터 저장/처리용 엔진으로 사용하고 Spark를 고급 분석용 모듈로 사용함으로써 이들 간의 시너지를 잘 활용하고 있습니다.
여기서는 Sparkline Data Inc.의 창업자 Harish Butani가 공개한 Druid vs Spark 성능 비교 보고서45의 내용을 간단히 소개합니다. 보고서에서는 애초에 두 솔루션이 경쟁 관계에 있다기 보다는 상보적인 역할을 한다고 상정을 하고 성능 비교를 시작합니다.
Apache Spark의 특징¶
Apache Spark는 오픈소스 클러스터 컴퓨팅 프레임워크로서 Java, Scala, Python, R 언어로 이루어진 다양한 API를 제공합니다. Spark의 프로그래밍 모델은 SQL, 머신러닝, 그래프 프로세싱을 결합한 분석 솔루션을 구축하는 것입니다. Spark는 규모가 크거나 복잡한 데이터를 가공할 수 있도록 강력한 기능들을 지원하지만, Druid와 같은 interactive한 쿼리 처리에 최적화되지는 않았습니다.
데이터셋, 쿼리, 성능 비교 결과¶
본 성능 비교를 위한 데이터셋으로 TPCH 10G benchmark data set을 이용했습니다. 본래 이 데이터셋은 관계형 데이터베이스에 적합한 스타 스키마 구조를 갖기 때문에 이를 역정규화시킨 후 Druid와 Spark에서 처리할 수 있도록 재구성하였습니다. 이러한 처리를 거친 데이터셋의 크기는 각각 다음과 같았습니다.
TPCH Flat TSV: 46.80GB
Druid Index in HDFS: 17.04GB
TPCH Flat Parquet: 11.38GB
TPCH Flat Parquet Partition by Month: 11.56GB
그런 다음 두 솔루션의 쿼리 처리 속도를 다각도에서 분석할 수 있는 여러 쿼리를 아래와 같이 구성하였습니다.
Druid와 Apache Spark의 query latency 비교 평가에 사용된 쿼리 내역¶ Query
Interval
Filters
Group By
Aggregations
Basic Aggregation.
None
None
ReturnFlag
LineStatusCount(*)
Sum(exdPrice)
Avg(avlQty)Ship Date Range
1995-12/1997-09
None
ReturnFlag
LineStatusCount(*)
SubQry
Nation, pType
ShpDt Range1995-12/1997-09
P_Type
S_Nation +
C_NationS_Nation
Count(*)
Sum(exdPrice)
Max(sCost)
Avg(avlQty)
Count(Distinct oKey)TPCH Q1
None
None
ReturnFlag
LineStatusCount(*)
Sum(exdPrice)
Max(sCost)
Avg(avlQty)
Count(Distinct oKey)TPCH Q3
1995-03-15-
O_Date
MktSegmentOkey
Odate
ShipPriSum(exdPrice)
TPCH Q5
None
O_Date
RegionS_Nation
Sum(exdPrice)
TPCH Q7
None
S_Nation +
C_NationS_Nation
C_Nation
ShipDate.YearSum(exdPrice)
TPCH Q8
None
Region
Type
O_DateODate.Year
Sum(exdPrice)
테스트 결과는 다음과 같았습니다.
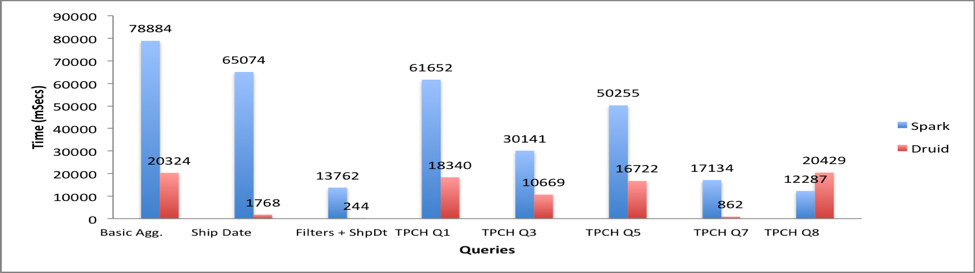
Source: Combining Druid and Spark: Interactive and Flexible Analytics at Scale¶
Filters + Ship Date 쿼리는 Druid에 특화된 slice-and-dice 성능을 테스트하는 것이었고, 예상대로 무려 50배 이상 속도 상에 우위를 보였습니다. 마찬가지로 TPCH Q7 쿼리를 처리하는 데도 Druid에서 수 밀리초가 소요된 반면, Spark에서는 수초가 소요되었습니다.
TPCH Q3, Q5, Q8 쿼리의 경우에는 Druid가 위 경우와 같은 극대화된 효율성을 보여주지 못했습니다. OrderDate 술어는 Druid에서 JavaScript 필터로 번역이 되는데, 이는 네이티브 Java 필터에 비해 현저히 느리기 때문입니다.
Basic Aggregation 및 TPCH Q1 쿼리의 경우에도 Druid에서 훨씬 빠른 처리 속도를 보여주었습니다. Druid에서는 Count-Distinct 동작이 cardinality aggregator로 번역이 되는데, 이는 approximate count에 해당합니다. 이러한 장점 덕에 Druid는 cardinality가 큰 차원들을 탐색할 때 유리합니다.
여러 가지 조건에 따라 결과는 달라질 수 있지만, 한 가지 분명한 것은 시간 파티셔닝(time partitioning) 또는 차원 술어(dimensional predicates)를 포함하는 쿼리는 Druid에서 현저히 빠르게 처리한다는 것입니다.
시사점¶
이러한 테스트 결과는 Druid의 초고속 쿼리 처리 능력과 Spark의 고급 분석 기능을 결합하면 아주 훌륭한 시너지 효과를 기대할 수 있음을 시사합니다. Druid를 통해 신속하고 효율적으로 분석에 필요한 데이터만 추려낸 후 Spark의 풍부한 프로그래밍 API들을 활용하여 심층적인 분석을 실시하는 것입니다. 이렇게 함으로써 강력하고 유연하며 쿼리 latency가 매우 낮은 분석 솔루션을 구축할 수 있습니다.
참고자료
- 1
Yang, E. Tschetter, X. Léauté, N. Ray, G. Merlino, and D. Ganguli. (2014). Druid: a real-time analytical data store. Retrieved from http://druid.io/docs/0.12.1/design/index.html.
- 2
Steven Acreman. (2016, Aug 26). Top 10 Time Series Databases. Retrieved from https://blog.outlyer.com/top10-open-source-time-series-databases.
- 3
DB-Engines website. https://db-engines.com, July 2018.
- 4
Harish Butani. (2018, Sep 18). Combining Druid and Spark: Interactive and Flexible Analytics at Scale. Retrieved from https://www.linkedin.com/pulse/combining-druid-spark-interactiveflexible-analytics-scale-butani.
- 5
Harish Butani. (2015, Aug 28). TPCH Benchmark. Retrieved from https://github.com/SparklineData/spark-druid-olap/blob/master/docs/benchmark/BenchMarkDetails.pdf.