Druid 특징¶
데이터 테이블 형태¶
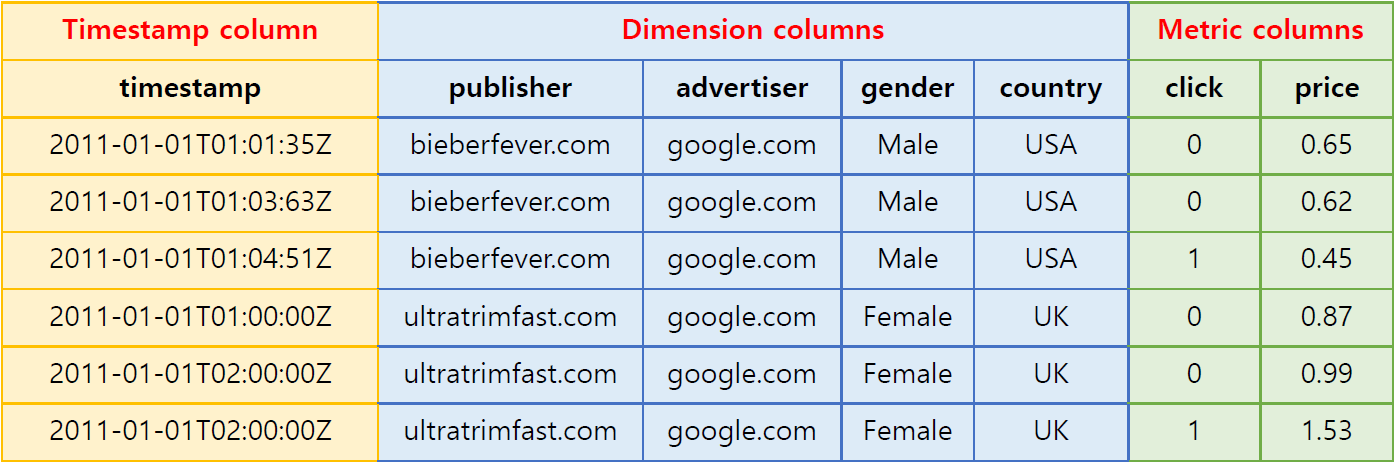
Druid의 데이터 테이블(Druid에서는 〈데이터 소스’라고 함)은 OLAP 쿼리용으로 설계된 시계열 이벤트들로 구성됩니다. 데이터 소스는 세 종류의 컬럼으로 구성됩니다(여기서는 온라인 광고 데이터를 예시로 사용).
Source: http://druid.io¶
타임스탬프 컬럼(Timestamp column): Druid는 데이터 소스에서 타임스탬프 컬럼을 별도로 구성함으로써 모든 쿼리가 시간 축을 중심으로 이루어지게 합니다(시계열 속성이 없는 데이터를 일괄적으로 ingestion할 경우에는 현재 시간을 기준으로 타임스탬프가 부여되어 Druid에서 활용할 수 있는 형태가 됩니다).
차원 컬럼(Dimension columns): 차원 컬럼은 각 이벤트의 문자열 속성들을 담고 있으며, 데이터 필터링 시 가장 흔히 사용됩니다. 위 데이터셋 예시에서는 publisher, advertiser, gender, country가 차원 컬럼입니다. 데이터 탐색 시에는 이러한 차원 컬럼들을 축으로 하여 데이터를 slice하게 됩니다.
측정값 컬럼(Metric columns): 측정값 컬럼들은 집계 및 연산에 사용됩니다. 위 예에서는 clicks 및 price가 측정값 컬럼입니다. 측정값 컬럼의 자료형은 대체로 수치 값이며, 이들은 계수, 합산, 평균 등의 방식으로 집계할 수 있습니다(Metatron에서는 지원되는 자료형을 증대하였습니다).
데이터 ingestion¶
Druid는 실시간 및 일괄(batch) ingestion을 지원합니다.
이 중에서 실시간 ingestion은 Druid의 주요 특징 중 하나인데, 이를 전담하는 real-time 노드군이 있기 때문에 가능한 것입니다(자세한 설명은 Real-time 노드 참조). 실시간으로 ingestion되는 데이터 스트림 내 이벤트들은 발생 후 수 초 이내에 Druid 클러스터에서 쿼리가 가능한 포맷으로 인덱싱됩니다.
데이터 roll-up¶
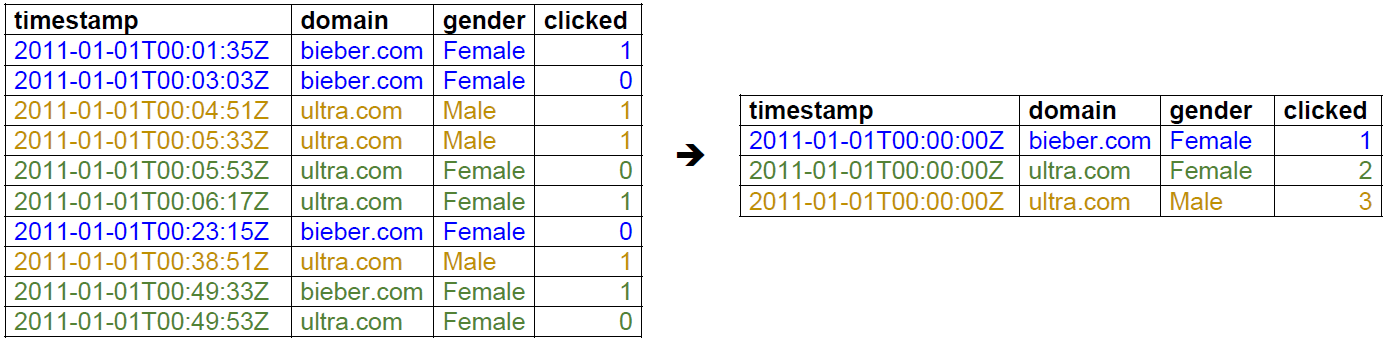
무수히 많은 개별 이벤트를 단순히 열거하기만 해서는 중요한 의미를 찾을 수 없습니다. 하지만 이러한 데이터를 적절한 시간대를 기준으로 취합하면 유용한 인사이트를 얻을 수 있습니다. Druid는 roll-up이라는 옵션을 통해 ingestion되는 원천 데이터를 취합할 수 있습니다. 아래는 roll-up의 예시를 나타낸 것입니다.
Source: Interactive Exploratory Analytics with Druid | DataEngConf SF 〈17¶
왼쪽의 원본 이벤트 목록은 2011년 1월 1일 00:00:00~01:00:00 사이에 발생한 도메인 클릭 이벤트를 열거한 것입니다. 하지만 분석가 입장에서는 분 이하 단위의 개별 이벤트가 별다른 의미를 갖지 못하기 때문에 1시간의 granularity를 기준으로 데이터를 취합했습니다. 그 결과 오른쪽 테이블에 나타난 것처럼 2011년 1월 1일 00~01시 시간대에 각 도메인을 남성과 여성이 각각 클릭한 횟수를 보여주는 보다 의미 있는 결과물이 도출되었습니다.
또한 데이터 roll-up은 원천 데이터의 저장 용량을 최소함으로써(많게는 100배까지도 축소 가능), 스토리지 리소스를 절약하고 쿼리 속도를 빠르게 합니다.
그러나 데이터를 roll-up하면 개별 이벤트들에 대해 쿼리할 수 없게 됩니다. roll-up granularity는 데이터를 탐색할 수 있는 최소 단위가 되며 이벤트들은 이러한 granularity 단위로 배열됩니다. granularity 단위는 사용자가 원하는 대로 설정할 수 있으며, 원치 않으면 roll-up을 비활성화하고 모든 개별 이벤트를 전부 ingestion할 수도 있습니다.
데이터 sharding¶
데이터 소스는 시계열 이벤트들의 집합으로서 여러 shard로 분할 저장되는데, Druid에서는 이를 〈세그먼트’라고 부르며 각 세그먼트는 대개 500~1,000만 행으로 이루어집니다. Druid는 데이터 소스들을 정의된 시간 간격(통상적으로 1시간이나 하루)을 기준으로 분할하며, 그 밖의 컬럼에 있는 값들을 기준으로 추가 분할을 실시함으로써 세그먼트 크기를 적절하게 맞출 수 있습니다.
아래는 1시간 단위로 분할된 데이터 테이블을 예시로 나타낸 것입니다.
세그먼트 sampleData_2011-01-01T01:00:00:00Z_2011-01-01T02:00:00:00Z_v1_0:
2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70
2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18
세그먼트 sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_0:
2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31
2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01
이와 같이 시간 단위로 세그먼트를 구분하는 것은 데이터 소스 내의 모든 이벤트에 타임스탬프가 포함되기 때문에 가능합니다.
세그먼트는 Druid 테이블의 기본 저장 단위에 해당하며, 클러스터 내 데이터의 복제(replication) 및 분산은 세그먼트 단위로 이루어집니다. 세그먼트 내 데이터는 변경할 수 없도록 되어 있습니다. 이렇게 함으로써 읽기와 쓰기 동작 사이에 경합이 발생하지 않게 됩니다. Druid의 세그먼트는 매우 신속하게 읽히기 위한 읽기 전용 데이터셋입니다.
뿐만 아니라, 이러한 데이터 세그먼트 분할은 Druid 분산 환경에서의 병렬 처리를 위한 핵심 역할을 합니다. 각 CPU가 한 번에 하나의 세그먼트를 스캔할 수 있기 때문에 데이터를 여러 세그먼트로 분할하면 이를 여러 CPU가 동시에 병렬적으로 스캔할 수 있으므로, 쿼리 결과를 신속하게 반환하고 부하를 안정적으로 분산시킬 수 있게 됩니다.
데이터 저장 포맷 및 인덱싱¶
Druid의 데이터 구조를 분석 쿼리에 최적화시키는 주요 요소 중 하나는 Druid가 데이터를 저장하는 방식입니다. 본 절에서는 설명을 위해 아래의 Druid 테이블 예시를 사용합니다.

Source: Druid: A Real-time Analytical Data Store¶
컬럼 기반 저장 및 인덱싱¶
Druid는 컬럼들을 각각 따로 저장합니다. Druid가 주로 이벤트 스트림을 집계하는 데 사용된다는 점을 고려할 때, 이러한 컬럼 기반 저장 방식을 취하면 각 쿼리에 관련된 컬럼만을 로드·스캔하므로 CPU 리소스를 보다 효율적으로 사용할 수 있습니다. 행 기반 데이터 스토어에서는 집계 시 대상 행과 관련된 모든 컬럼을 컬럼별로 상이한 방식으로 압축할 수 있으며 그에 따라 각기 다른 인덱스를 활용함으로써 컬럼을 메모리나 디스크에 저장하는 데 드는 리소스 비용을 줄일 수 있습니다. 위 예에서 page, user, gender, city 컬럼은 문자열만을 포함합니다. 직접 문자열들을 저장하는 것은 불필요한 비용을 발생시키므로 이들을 고유한 정수 식별자로 매핑할 수 있습니다. 예를 들면,
Justin Bieber -> 0
Ke$ha -> 1
이 매핑을 사용하면 page 컬럼을 정수 배열로 나타낼 수 있는데, 여기서 배열 인덱스 각각은 원본 데이터셋의 각 행에 해당합니다. page 컬럼의 경우, 각 행의 page 값을 아래와 같이 표시할 수 있습니다.
[0, 0, 1, 1]
이처럼 문자열들이 고정 길이 정수들로 바뀌어 저장되므로 압축하기가 훨씬 더 수월합니다. Druid는 각 shard(세그먼트) 단위로 데이터를 인덱싱합니다.
데이터 필터링을 위한 인덱싱¶
Druid는 검색 인덱스를 추가로 만들어서 문자열 컬럼에 대한 필터링을 용이하게 할 수 있습니다. 위 예시 테이블을 다시 보자. 가령 《샌프란시스코에 사는 남성 사용자들이 Wikipedia 편집을 한 횟수는?》과 같은 쿼리가 있을 수 있습니다. 이 쿼리 예시에는 도시(San Francisco)와 성별(Male)이라는 두 가지 차원이 포함됩니다. 각 차원별로 아래와 같은 바이너리 배열이 생성되는데, 여기서 배열 인덱스 각각은 해당 행이 쿼리 필터 조건에 부합하는지 여부를 나타냅니다.
San Francisco (City) -> rows [1] -> [1][0][0][0]
Male (Gender) -> rows [1, 2, 3, 4] -> [1][1][1][1]
그런 다음 쿼리 필터는 이러한 두 배열에 대해 AND 연산을 실시합니다.
[1][0][0][0] AND [1][1][1][1] = [1][0][0][0]
그 결과, 행 1만 스캔 대상이 됩니다. 이런 식으로 필터링된 행만 검색함으로써 불필요한 부하를 방지하는 것입니다. 이러한 바이너리 배열은 압축하기도 매우 쉽습니다.
이러한 검색 인덱싱은 OR 연산에도 사용할 수 있습니다. 어떤 쿼리가 San Francisco 또는 Calgary을 필터링하는 경우, 배열 인덱스들은 차원값별로 다음과 같을 것입니다.
San Francisco (City) -> rows [1] -> [1][0][0][0]
Calgary (City) -> rows [3] -> [0][0][1][0]
그런 다음 두 배열에 대해 OR 연산이 수행됩니다.
[1][0][0][0] OR [0][0][1][0] = [1][0][1][0]
그 결과, 쿼리는 행 1과 3만 스캔합니다.
대형 비트맵 셋에 boolean 연산을 실시하는 이러한 접근방식은 검색 엔진에서 널리 사용됩니다.
쿼리 언어¶
Druid의 네이티브 쿼리 언어는 JSON over HTTP이며, 주요 쿼리는 다음과 같습니다.
Group By
시계열 기반 roll-up
임의적 boolean 필터링
Sum, Min, Max, Avg 등의 집계 연산
차원값 검색
하지만 이 외에도 SQL을 비롯한 다양한 언어로 이루어진 쿼리 라이브러리가 생성·공유되고있습니다.